Javascript 기반이고, 개발 구조가 매우 단순화 되어 있어서 빠르게 개발이 가능하다.
즉 클라이언트에서 front end를 자바스크립트를 통해서 개발하던 FE(front end) 개발자들도 손쉽게 서버 프로그래밍이 가능하다는 것이고,
조직의 입장에서도 FE와 BE(BackEnd) 엔지니어의 기술셋을 나눌 필요가 없다는 것이다.
node.js가 빠르다고는 하지만, 실제 성능보다는 이러한 Learning curve나, 조직내의 FE/BE 기술 통합에서 오는 장점이 더 큰 이유가 아닐까 싶다.
다음으로는 socket.io를 이용한 웹 push 구현이 매우 쉽게 구현이 가능하다.
여타 플랫폼도 WebSocket을 이용한 Push 를 지원하기는 하지만, WebSocket은 브라우져 종류나 버전에 따라서 제한적으로 동작한다.
node.js의 경우 웹브라우져의 종류에 따라서 WebSocket뿐만 아니라, Long Polling등 다른 push 메커니즘을 브라우져 종류에 따라서 자동으로 선택하여 사용하고 있으며,
이러한 push 메커니즘은 socket.io API 내에 추상화 되어 있기 때문에, 어떤 기술로 구현이 되어 있던간에 개발자 입장에서는 socket.io만 쓰면 간단하게 웹 기반의 push 서비스가 구현이 가능하다.
마지막으로, non-blocking IO 모델을 지원하는데, 뒤에서 자세하게 설명하겠지만, 일반적인 서버들은 io 요청을 보낸후, 요청을 보낸 thread나 process가 io 요청이 끝날 때 까지 io wait 상태로 응답을 기다리고 있다.
이로 인해서, 동시에 서비스할 수 있는 클라이언트 수 (thread가 계속 기다리기 때문에)에 제약이 있고, CPU 사용 효율에도 제약을 갖는다.
이러한 문제를 해결하기 위해서 node.js는 non-blocking io 컨셉을 사용하는데, io 요청이 있으면, io 처리를 던져 놓고, thread나 process는 다른 일을 하고 있다가, io 처리가 끝나면 이에 대한 이벤트를 받아서, 응답을 처리하는 형태가 된다.
<내용>
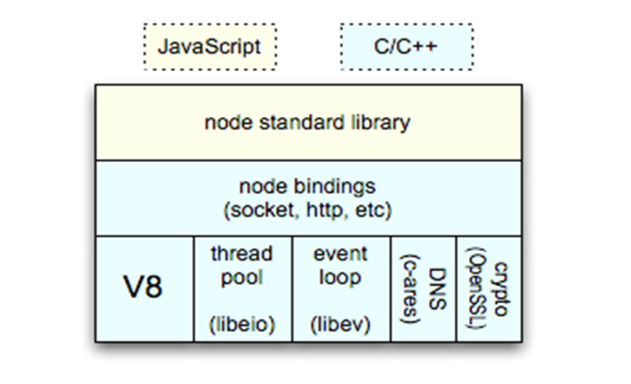
V8 Engine
<내용>
<내용>
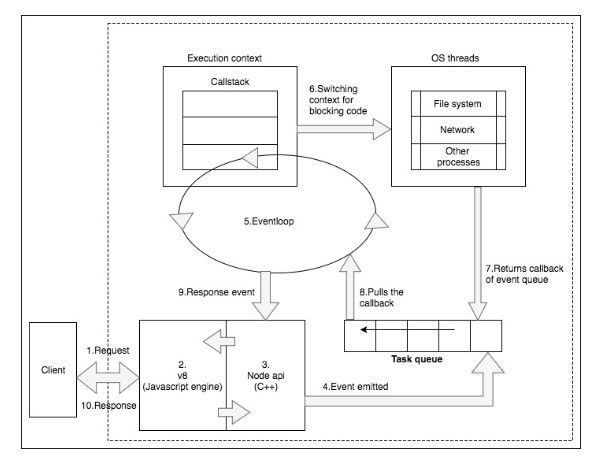
Async / Non blocking IO
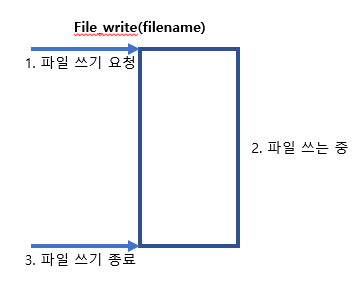
먼저 동기식 IO는 다음과 같이 동작한다. file write io를 예를 들어보면, file_write를 호출하면, 디스크에 파일 쓰기 요청을 하고,
디스크가 파일을 쓰는 동안 프로그램은 file_write 부분에 멈춰서 대기하게 된다. (블록킹상태).
파일을 쓰는 동안에는 CPU가 사용되지 않기 때문에, CPU는 놀고,파일이 다 써지만 디스크에서 리턴해서 file_write 함수 다음 코드로 진행을 하게 된다.
<내용>
<내용>
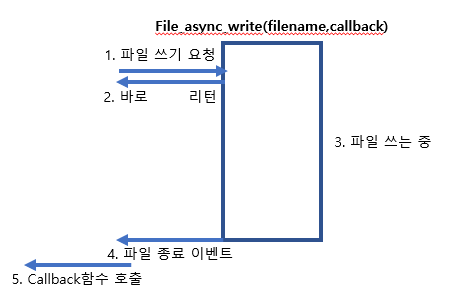
파일 쓰기 요청을 할 때, 파일 요청이 끝나면 호출될 함수(callback)를 같이 넘긴다.
파일 쓰기 요청이 접수되면 프로그램은 파일이 다 써지는 것을 기다리지 않고, 요청만 던지고 다음 코드로 진행을 계속한다.
파일을 다 쓰고 나면 앞에서 등록했던 callback 함수를 호출하여 파일 쓰기가 다 끝났음을 알리고 다음 처리를 한다.
비교를 해서 설명하자면 파일 쓰기가 떡볶이를 주문하는 과정이라면, 앞의 블록킹 IO 방식의 경우에는 떡볶이를 주문해놓고,
나오기 까지 기다리고 있는 형태라면, 비동기식 방식은 떡볶이를 주문해놓고, 나가서 다른 일들을 하다가 나오면,
가 나왔으니 가져가라고 전화(이벤트)를 하는 형태가 된다.
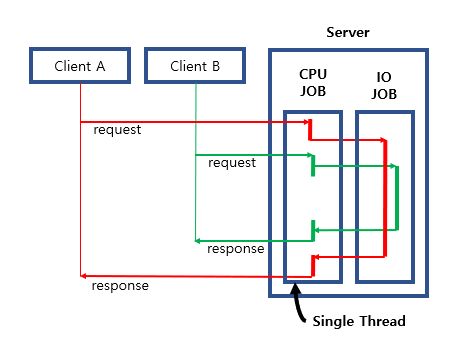
Single Thread Model
하나의 Thread만을 사용해서 여러 Client로부터 오는 Request를 처리한다.
단, IO 작업이 있을 경우 앞에서 설명한 비동기 IO방식으로 IO 요청을 던져놓고,
다시 돌아와서 다른 작업을 하다가 IO 작업이 끝나면 이벤트를 받아서 처리하는 구조이다.
아래 그림에서 처럼, Client A가 요청을 받으면, CPU 작업을 먼저하다가 IO작업을 던져놓고,
Client B에서 요청이 오면, CPU작업을 하다가 IO작업을 던져놓고,
Client A의 IO작업이 끝나면 이를 받아서 Client A에 리턴하는 식의 구조이다.
IO작업시 기다리지 않기 때문에(Block 되지 않기 때문에), 하나의 Thread가 다른 요청을 받아서 작업을 처리할 수 있는 구조가 된다.
이 요청을 받아서 처리하는 Thread를 ELP (Event Loop Thread)라고 한다.
<내용>
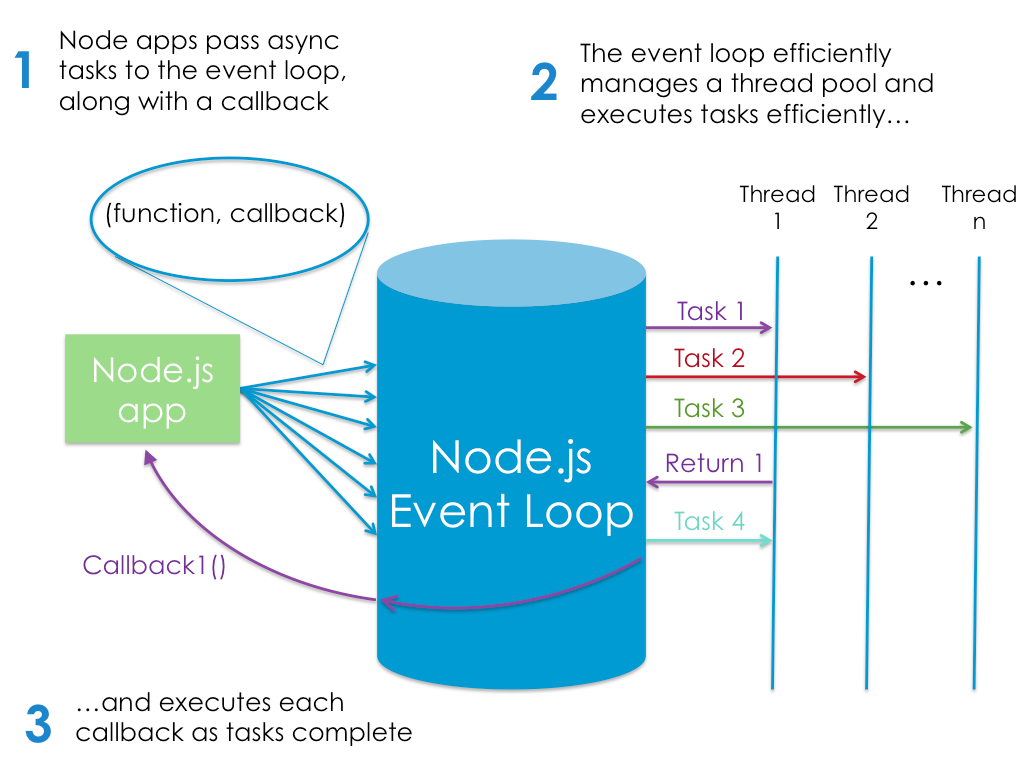
Thread pool
<내용>
Node.js도 single thread만 사용하는 것이 아니라 내부적으로 multi thread pool을 사용하기는 한다.
예를 들어 file open등과 같은 일부 IO는 OS에 따라서 nonblocking function을 지원하지 않는 경우가 있기 때문에,
이러한 blocking io function을 호출할 경우에는 어쩔 수 없이 blocking이 발생하는 데,
이 경우 single thread로 구현된 event loop thread가 정지되기 때문에 이러한 문제를 해결 하기 위해서 내부적으로 thread pool을 별도로 운영하면서
blocking function call의 경우에는 thread pool의 thread를 이용하여 IO 처리를 하여 event loop thread가 io에 의해서 block되지 않게 한다.
Thread pooling 배경
기본적인 쓰레드프로그래밍 기법은 쓰레드를 생성시켜야 될 필요가 있을때 새로운 작업쓰레드를 생성시키는 방식을 사용했다.
보통 쓰레드프로그래밍은 네트웍 프로그래밍시 주로 사용된다.
쓰레드 프로그래밍기법은 대부분의 작업을 처리하기에 충분히 효율적이며, 빠르긴하지만 클라이언트로 부터의 연결과 종료가 매우 바쁘게 일어나는 서버의 경우,
계속적으로 쓰레드를 생성하고 종료해야 하는 비용을 무시할수 없게 된다.
Thread Pooling 은 이러한 반복적인 쓰레드의 생성/소멸에 의한 비효율적인 측면을 없애고자 하는 목적으로 만들어진 프로그래밍 기법이다.
<내용>
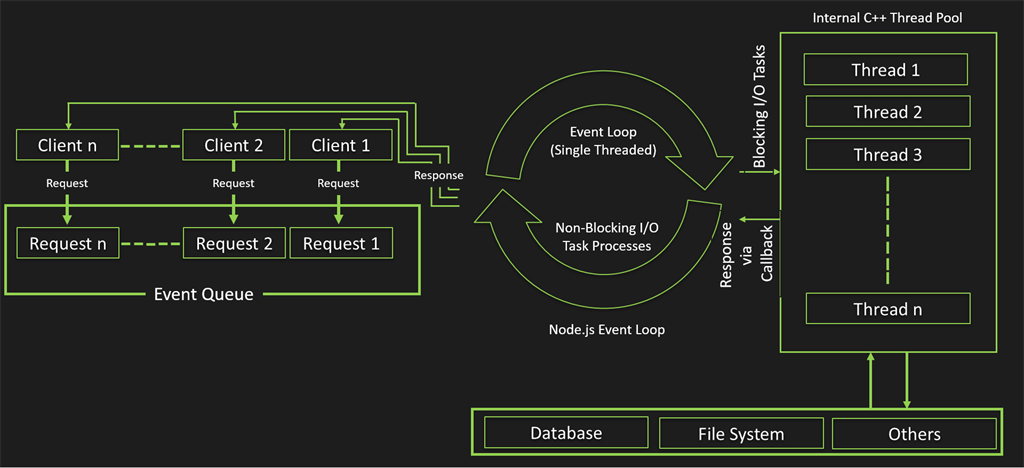
Event Loop
이 하나의 Thread로 여러 클라이언트의 요청, 즉 여러 개의 socket connection을 어떻게 처리할까?
방법은 Multiplexing에 있다.
여러 개의 socket이 동시에 연결되어 있는 상태에서 하나의 Thread는 어느 socket으로부터 메시지가 들어오는 지 보다가,
socket에서 메시지가 들어오면, 그 메시지를 꺼내 받아서 처리를 하는 방식이다. (epoll, kqueue, dev/poll ,select등을 이용)
<내용>
단 이런 single thread 모델에서 주의해야 하는 점은 CPU 작업이 길어질 경우에는 다음 request를 처리하지 못하기 때문에,
다음 request처리가 줄줄이 밀려버릴 수 있다는 것이다. 예를 들어 보자 커피 전문점이 있다고 보자, 주문을 받는 사람이 Single Thread이다.
커피 주문이 들어오면 들어오면 주방에서 일하는 사람에게 커피 주문을 넘기고, 다음 고객의 주문을 받는다.
앞에서 주문한 커피가 주방에서 나오면 이를 주문한 사람에게 커피를 넘겨준다.
커피 주문을 request, 커피를 response, 그리고 커피를 만드는 과정을 IO라고 생각해보자.
만약에 커피를 주문받거나 커피를 건네주는 과정에 많은 시간이 소요된다면 (CPU 작업이 많다면), 뒤에 손님이 기다리는 일이 발생하게 된다.
예를 들어 주문에 1분씩 소요된다면, 첫번째 손님은 1분을, 두번째는 2분을… 60번째는 60분을 기다리게 된다.
그래서 이러한 single thread model에서는 각 request가 CPU를 많이 사용하는 경우 request 처리가 줄줄이 지연되면서
성능에 심각한 영향을 줄 수 있기 때문에 CPU intensive한 작업에는 적절하지가 않다.


 <내용>
<내용>
 <내용>
<내용>
 <내용>
<내용>
 <내용>
<내용>
 <내용>
<내용>
 <내용>
<내용>
 <내용>
<내용>
 <내용>
<내용>
 <내용>
<내용>
 <내용>
<내용>