

JavaScript Engine
25 Dec 2018 | JavaScript이 글은 https://velog.io/@godori/JavaScript-%EC%97%94%EC%A7%84-%ED%86%BA%EC%95%84%EB%B3%B4%EA%B8%B0-mdjowmjlcb에서 발췌한 내용이고 고급 개발자가 되기 위해서는 엔진이 어떻게 돌아가는지를 이해해야하기 때문에 자바스크립트 엔진이 어떤식으로 돌아가는지 공부하기위해 가져오고 정리하였습니다.
자바스크립트 엔진이란?
JS 코드를 실행하는 프로그램 또는 인터프리터를 말합니다.자바스크립트 엔진의 종류
자바스크립트는 웹 브라우저뿐만 아니라 Node.js, Electron, React Native 등의 프로젝트와 그 밖의 다양한 곳에서 동작합니다.V8
C++로 작성되었으며, 구글이 개발한 오픈소스입니다. Google Chrome, Electron, Node.js에서 사용합니다.
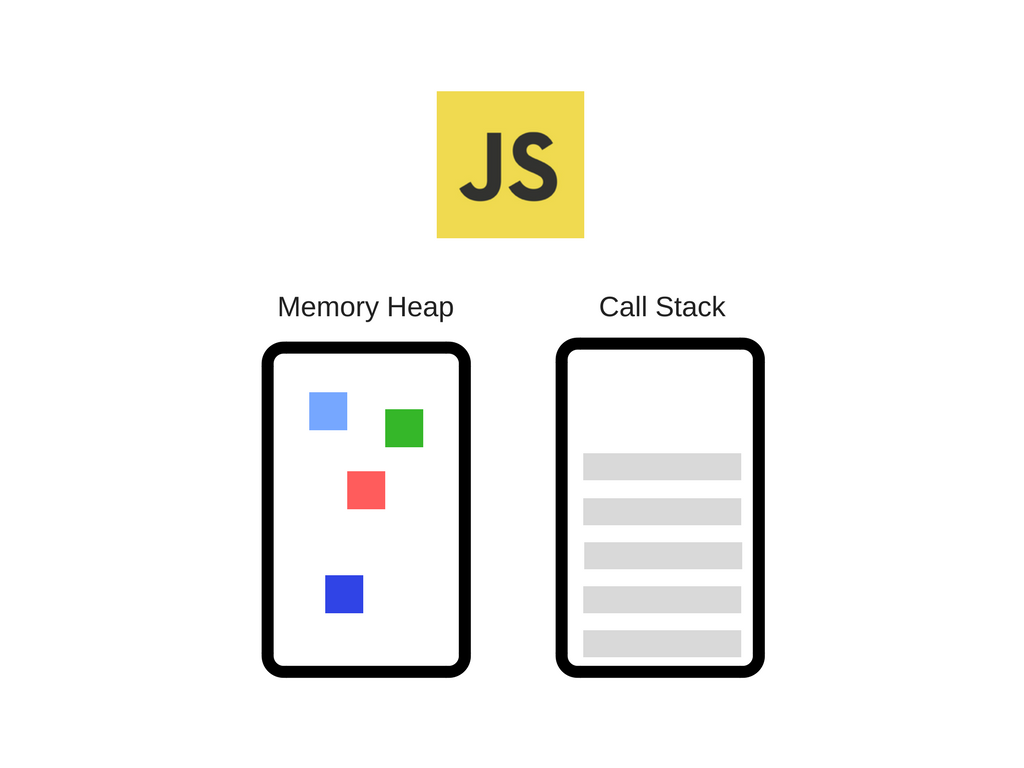 <내용>
<내용>
자바스크립트 엔진 파이프라인
자바스크립트 엔진들이 소스 코드를 기계어로 만들기까지 공통적으로 수행하는 과정을 살펴봅시다.
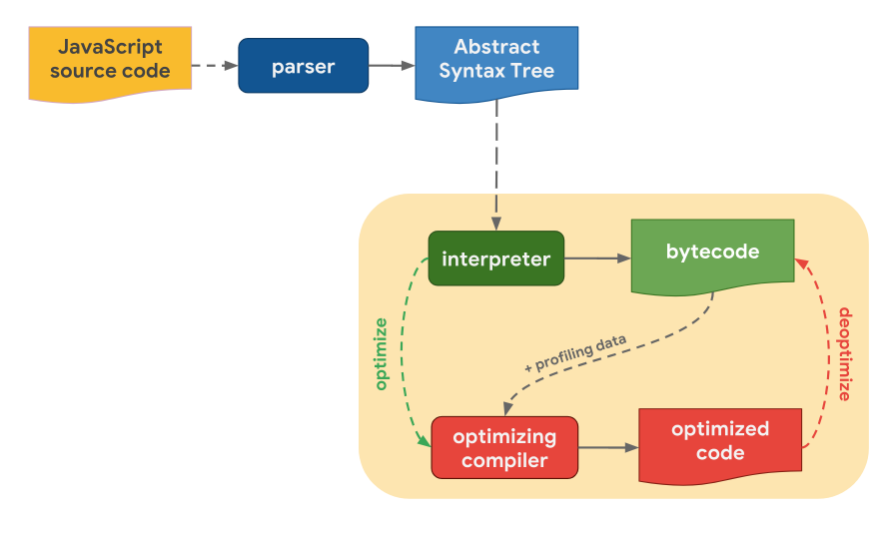 <내용>
<내용>
인터프리터/컴파일러 파이프라인
인터프리터가 코드를 해석하고, 최적화 할 때 주요 자바스크립트 엔진들 사이에 어떤 차이가 있는지 알아봅시다. 일반적으로는 다음과 같은 공통된 파이프라인을 가집니다.
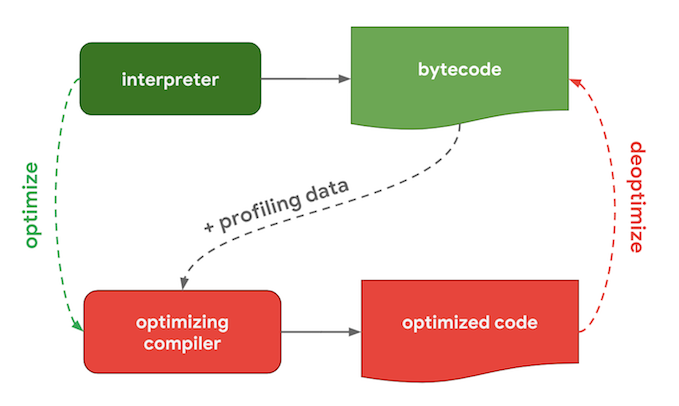 <내용>
<내용>
인터프리터(interpreter)
: 최적화되지 않은 바이트코드(bytecode)를 빠르게 생성합니다.최적화 컴파일러(optimizing compiler)
: 매우 최적화된 기계어 코드(machine code)를 약간 시간을 들여서 생성합니다. 이 과정에서 바이트코드는 중간 언어(IR, intermediate representation)입니다. 만약 interpreter 모드라면 바이트코드를 하나씩 읽어서 실행하고, JIT 모드라면 바이트 코드를 기반으로 컴파일하여 수행합니다. 바이트코드(Bytecode, portable code, p-code)는 특정 하드웨어가 아닌 가상 컴퓨터에서 돌아가는 실행 프로그램을 위한 이진 표현법이다. 하드웨어가 아닌 소프트웨어에 의해 처리되기 때문에, 보통 기계어보다 더 추상적이다. JIT 컴파일(just-in-time compilation)또는 동적 번역(dynamic translation)은 프로그램을 실제 실행하는 시점에 기계어로 번역하는 컴파일 기법이다. 이 기법은 프로그램의 실행 속도를 빠르게 하기 위해 사용된다.V8에서 처리하는 방법
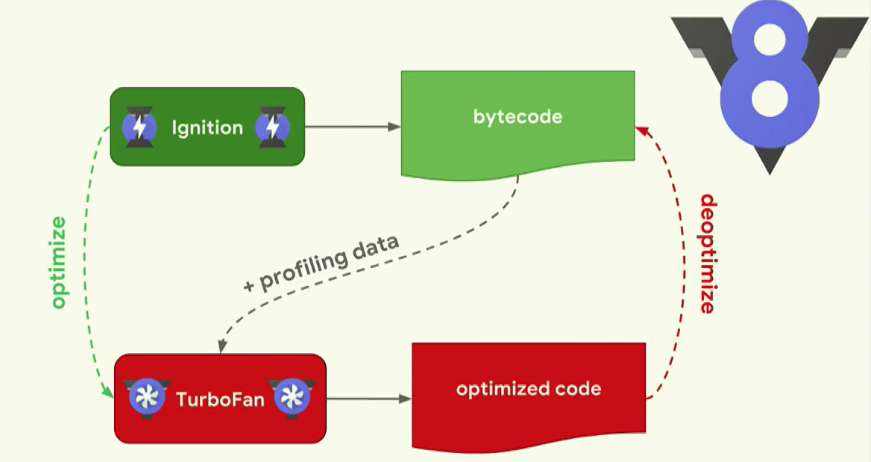 <내용>
<내용>
뜨거워진다(getting hot)의 의미?
자주 반복돼서 수행된다는 뜻입니다. 최근의 JS 엔진들은 일괄적으로 최적화를 적용하는 JITC가 아닌 Adaptive Compilation방식을 택하고 있습니다. 이는 반복 수행되는 정도에 따라 서로 다른 최적화를 적용하는 것입니다. 처음에 모든 코드는 인터프리터에 의해 바이트 코드로 변환되지만, 자주 반복되는 부분이 발견되면 여기에 대해서만 JITC를 적용하는 식입니다.처리 방법의 차이점과 공통점
왜 어떤 엔진은 더 많은 최적화 컴파일러를 갖고 있을까요? 바로 트레이드 오프(trade-offs) 때문입니다. 인터프리터는 바이트코드를 빠르게 생성할 수 있지만 효율적인 코드가 아닙니다. 반대로 최적화 컴파일러는 시간이 조금 더 걸리지만 훨씬 효율적인 기계 코드를 생성합니다. 따라서, 어떤 엔진은 여러 개의 최적화 컴파일러를 선택함으로써 복잡해지는 비용을 감수하고 이러한 인터프리터와 컴파일러 사이의 균형을 필요에 따라 세부적으로 제어할 수 있도록 한 것입니다. 결국, 자바스크립트 엔진마다 구체적인 최적화 과정은 차이가 있으나, 파서와 인터프리터/컴파일러가 포함된 동일한 아키텍쳐로 구성된 것을 알 수 있습니다.JS 엔진이 객체 모델을 구현하는 방법
객체의 정의
객체는 JS 명세에 따르면 String으로 된 키와 이것으로 접근할 수 있는 값들을 가지고 있는 딕셔너리입니다. 이 키는 단순히 [[value]]에 맵핑되는 것 뿐만 아니라 속성 값(property attributes) 이라고 하는 스펙에도 매핑됩니다.
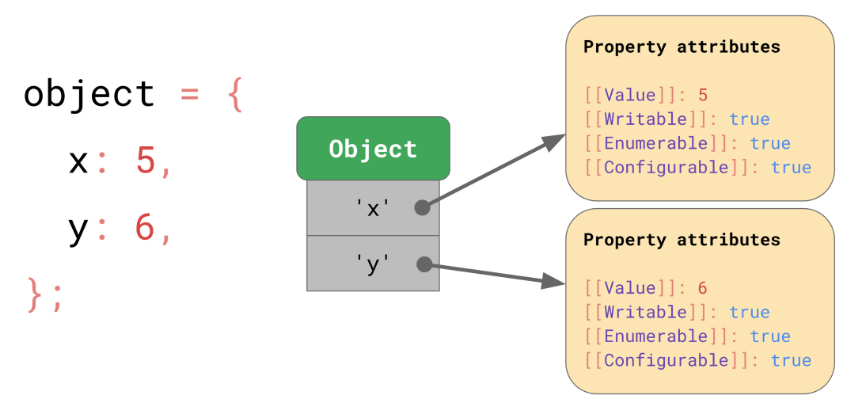 <내용>
<내용>
속성 값(property attributes)
객체는 기본적인 속성 값으로 [[Writable]], [[Enumerable]], [[Configurable]] 상태를 가집니다.
 <내용>
<내용>
const object = { foo: 42 };
Object.getOwnPropertyDescriptor(object, 'foo');
// => {value: 42, writable: true, enumerable: true, configurable: true}
JS의 배열
배열은 조금 다르게 처리하는 특별한 객체라고 생각하면 됩니다. 객체와 다른 배열만의 특징은 다음과 같습니다.인덱스(index)가 존재한다.
배열 인덱스는 무엇일까요? 그것은 제한된 범위가 있는 정수입니다. JS 명세에 따르면, 배열은 2³²-1 개 까지의 아이템을 가질 수 있습니다. 따라서 배열 인덱스는 0 부터 2³²-2 까지의 범위에서만 인덱스로 유효한 정수 값입니다.길이(length) 정보를 가집니다.
length property는 마치 마법 같은 것이라고 할 수 있습니다. 배열에 아이템을 추가하면 length property는 저절로 늘어나기 때문입니다! 이 작업은 사실 엔진에서 자동으로 해주는 겁니다.
const array = ['a', 'b'];
array.length; // 2
array[2] = 'c';
array.length; // 3
JS 엔진에서 배열을 다루는 방법
기본적으로 객체와 비슷합니다. 배열은 인덱스를 포함하여 모두 string 키를 가집니다. 아래 그림을 보면 인덱스인 '0' 은 'a'라는 값을 가지며, 값을 바꿀 수 있고(Writable), 열거 가능하고(Enumerable), 삭제 가능(Configurable) 합니다. 또 다른 프로퍼티인 length 의 값은 1이며, 값을 바꿀 수 있지만 열거와 삭제가 불가능 합니다.
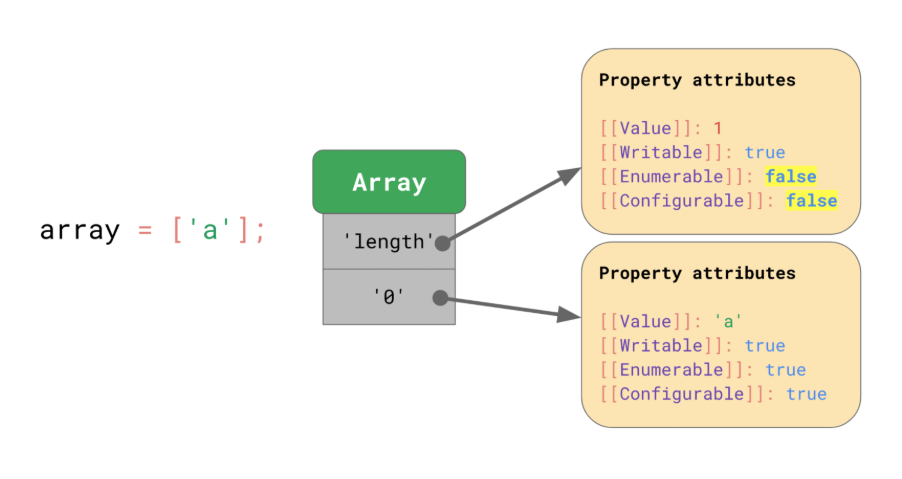 <내용>
<내용>
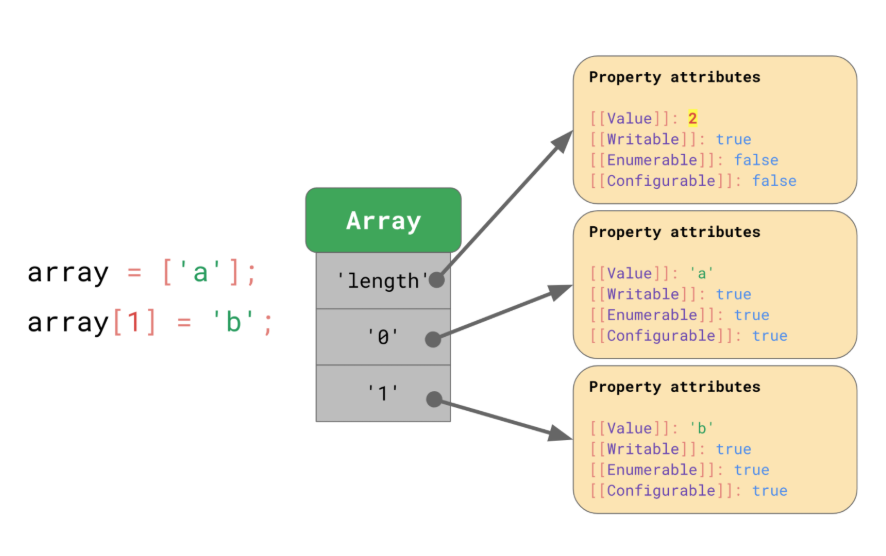 <내용>
<내용>
엔진의 프로퍼티 접근 최적화
Shape == Hidden Class
function logX(obj){
console.log(obj.x);
}
const obj1 = { x:1, y:2 };
const obj2 = { x:3, y:4 };
logX(obj1);
logX(obj2);
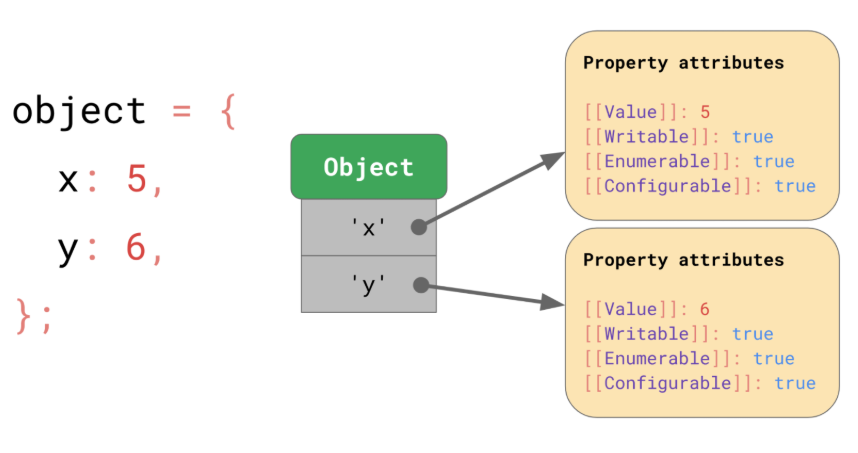 <내용>
<내용>
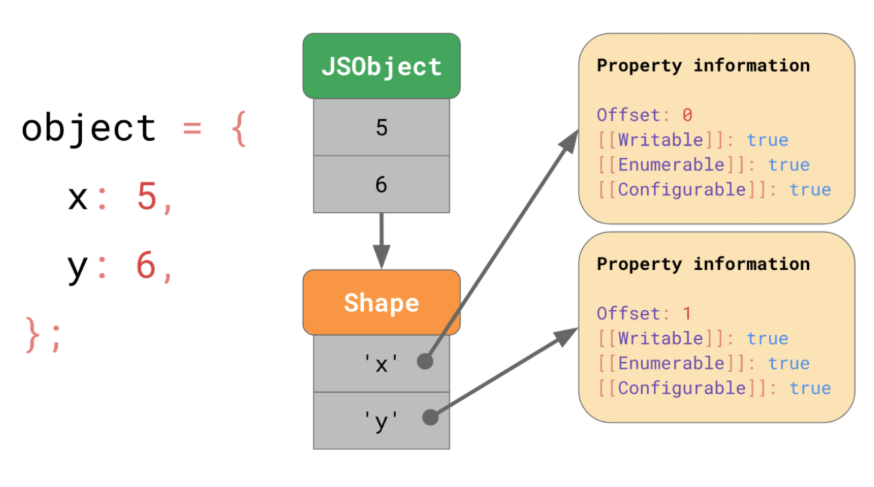 <내용>
<내용>
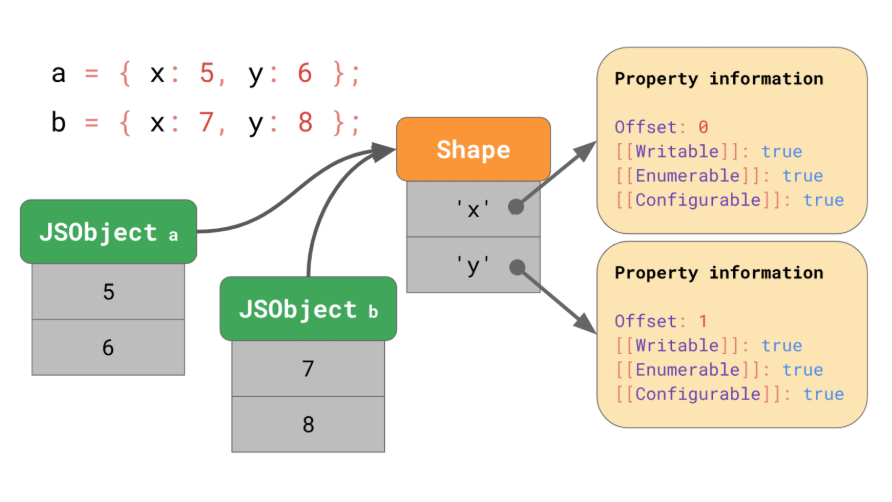 <내용>
<내용>
const o = {};
o.x = 5;
o.y = 6;
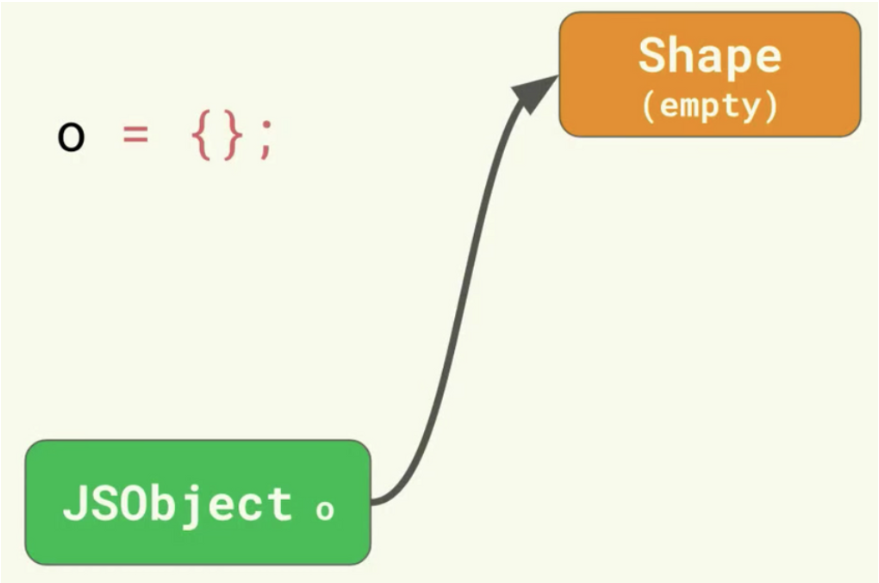 <내용>
<내용>
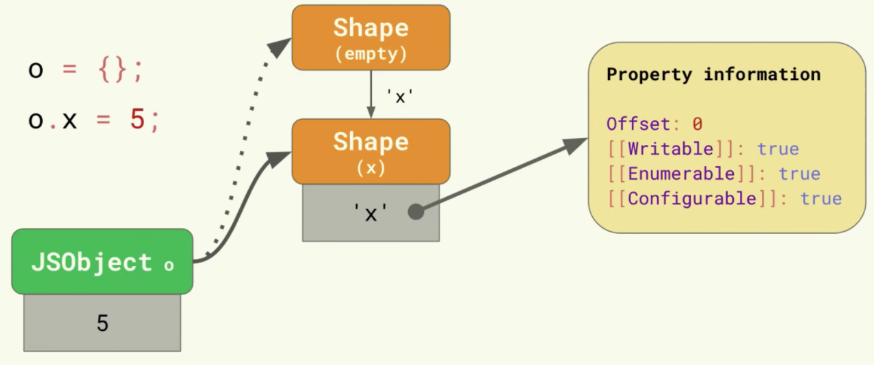 <내용>
<내용>
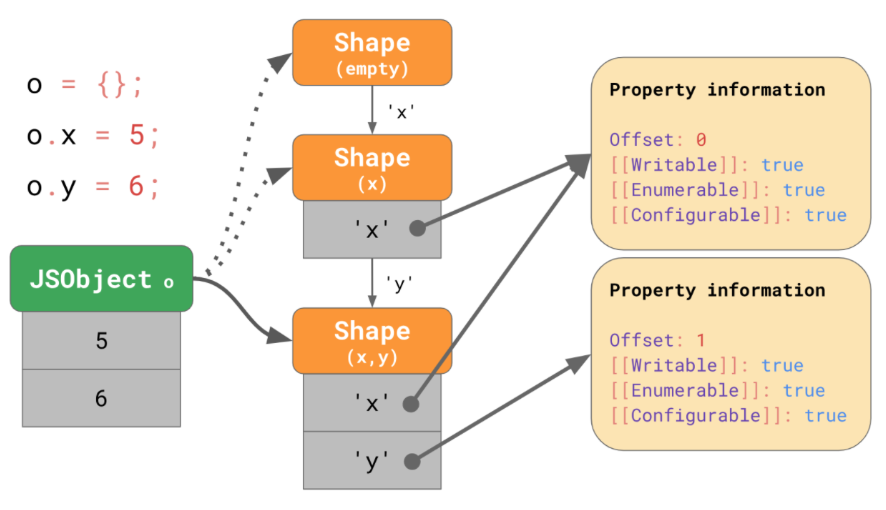 <내용>
<내용>
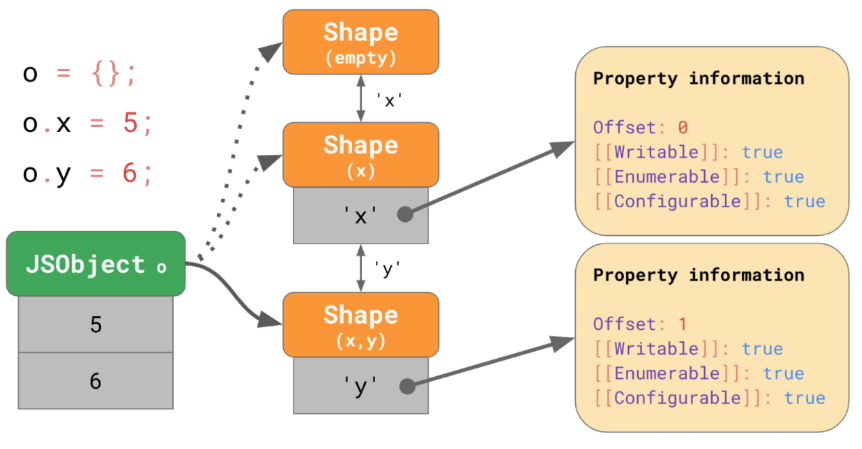 <내용>
<내용>
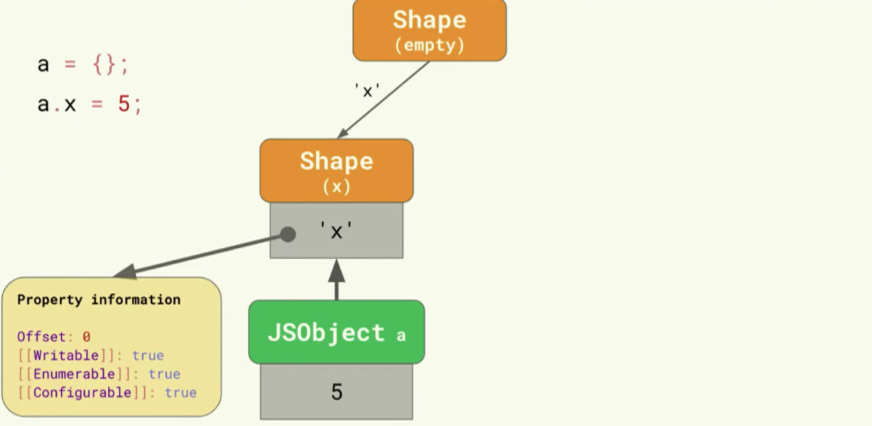 <내용>
<내용>
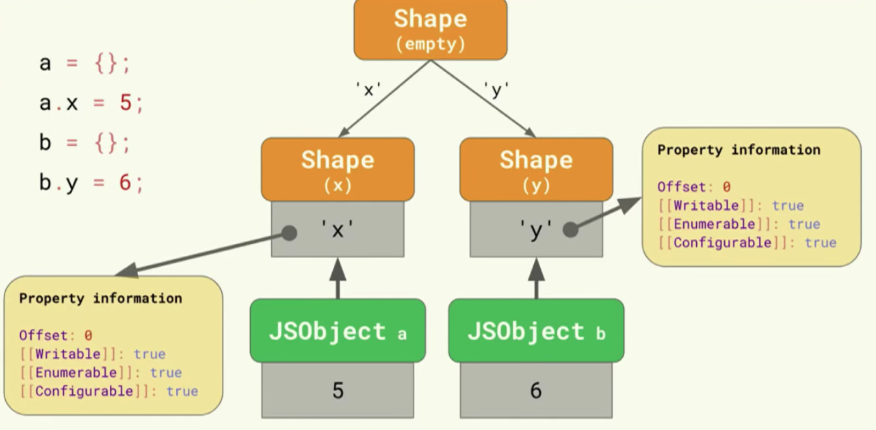 <내용>
<내용>
const obj1 = {};
obj1.x = 6;
const ob2 = {x: 6};
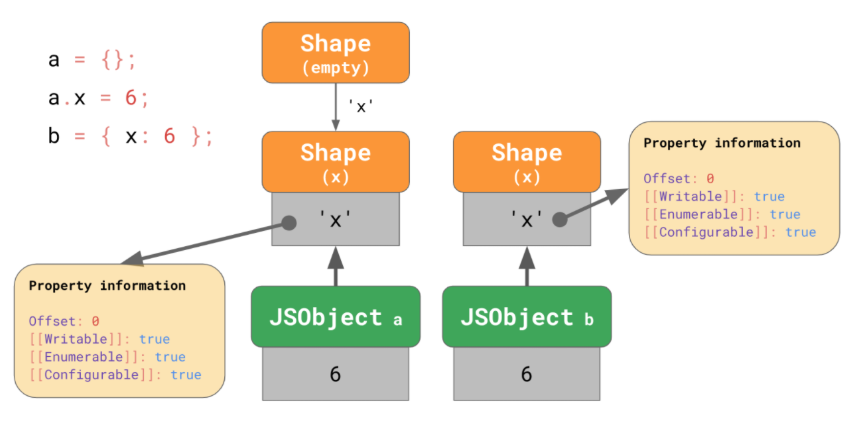 <내용>
<내용>
const point = {};
point.x = 4;
point.y = 5;
point.z = 6;
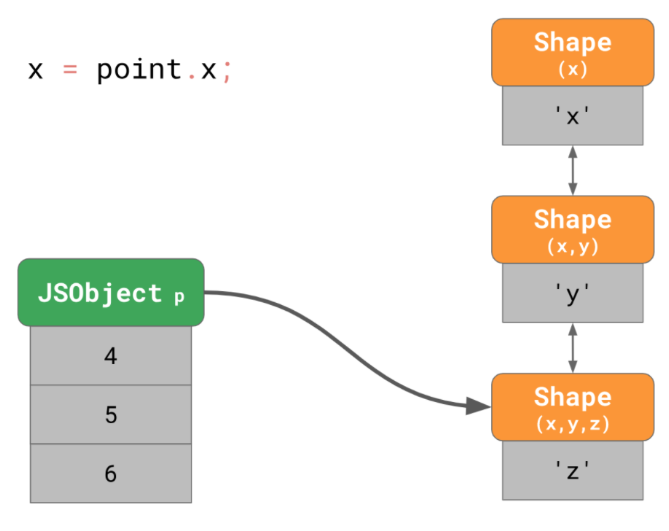 <내용>
<내용>
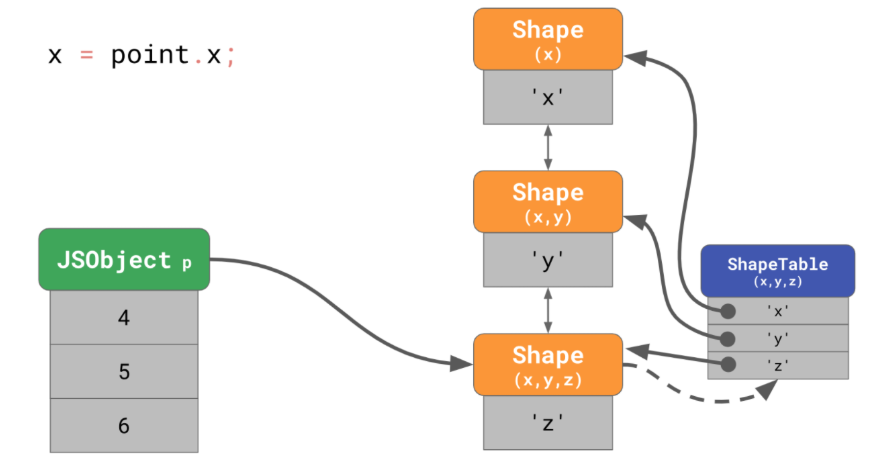 <내용>
<내용>