Apache Kafka(아파치 카프카)는 LinkedIn에서 개발된 분산 메시징 시스템으로써 2011년에 오픈소스로 공개되었다.
대용량의 실시간 Log처리에 특화된 아키텍처 설계를 통하여 기존 메시징 시스템보다 우수한 TPS를 보여주고 있다.
카프카는 비동기 처리를 위한 메시징 큐의 한 종류이며, 프로듀서와 컨슈머가 있습니다.
대표적인 비동기 메시징 시스템인 메일과 비교하면 이해가 쉽게 될 것 같습니다.
우리가 잘 알고 있는 메일의 경우 보내는 사람은 받는 사람과 상관 없이 메일 서버로 메시지를 보낼 수 있습니다.
보낸 메시지는 메일서버에 저장되어 있고, 받는 사람은 자기가 원하는 시간에 언제든지 메일을 볼 수 있게 됩니다.
카프카도 비슷합니다.
프로듀서는 카프카로 메시지를 보내게 되고, 해당 메시지는 카프카에 저장되어 보관중입니다.
그리고 컨슈머는 카프카에 저장되어 있는 메시지를 필요로 할때, 가져갈 수 있습니다.
<내용>
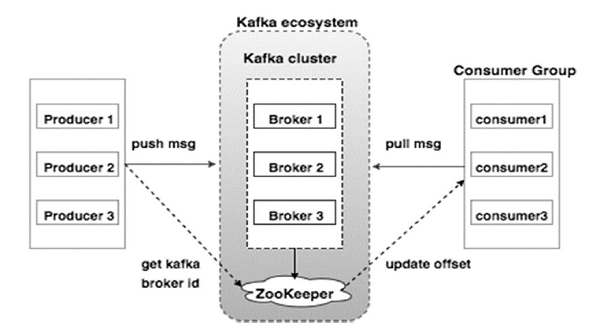
중요 개념 요약:Producer : 메세지 생산(발행)한다.
Consumer : 메세지 소비자
Consumer Group : Consumer들끼리 메세지를 나눠서 가져간다. Offset 을 공유하여 중복으로 가져가지 않는다.
Broker : 카프카 서버를 가리킨다.
Zookeeper : 카프카 서버 (+클러스터) 상태를 관리한다.
Cluster : 브로커들의 묶음을 말한다.
Topic : 메세지 종류를 뜻한다.
Partitions : Topic 이 나눠지는 단위이다.
Log : 1개의 메세지를 말한다.
Offset : 파티션 내에서 각 메시지가 가지는 Unique Id를 말한다.
<내용>
기본 개념에서 알았으니, 이제 카프카에 대해서 살펴보겠습니다.
Topic 및 Log
먼저 Kafka가 제공하는 핵심 추상화에 대해 알아봅시다.
Topic은 레코드가 공개되는 카테고리 또는 피드 이름입니다.
카프카의 Topic은 항상 Multi-Subscribe입니다.
즉, Topic에는 기록 된 데이터를 구독하는 0, 1 또는 많은 사용자가있을 수 있습니다.
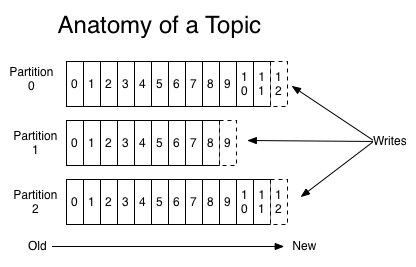
각 Topic에 대해 카프카 클러스터는 다음과 같은 Partition Log를 유지합니다.
<내용>
각 Partition은 순서화되고 변하지 않는 레코드의 순서이고 이 레코드 순서는 계속해서 추가되는 구조화된 커밋 Log입니다.
Partition의 레코드에는 Partition 내의 각 레코드를 고유하게 식별하는 Offset이라는 순차적인 ID 번호가 각각 할당 됩니다.
Kafka 클러스터는 설정가능한 보존 기간을 사용하여 게시된 모든 레코드를 영구히 유지합니다.
예를 들어 보존 정책을 2일로 설정하면 레코드를 게시한 후 2일 동안 소비정책을 사용할 수 있으며
그 이후에는 사용 가능한 공간을 늘리기 위해 폐기됩니다.
Kafka의 성능은 데이터 크기와 관련하여 실질적으로 일정하므로 데이터를 오랫동안 저장하는 것은 문제가 되지 않습니다.
<내용>
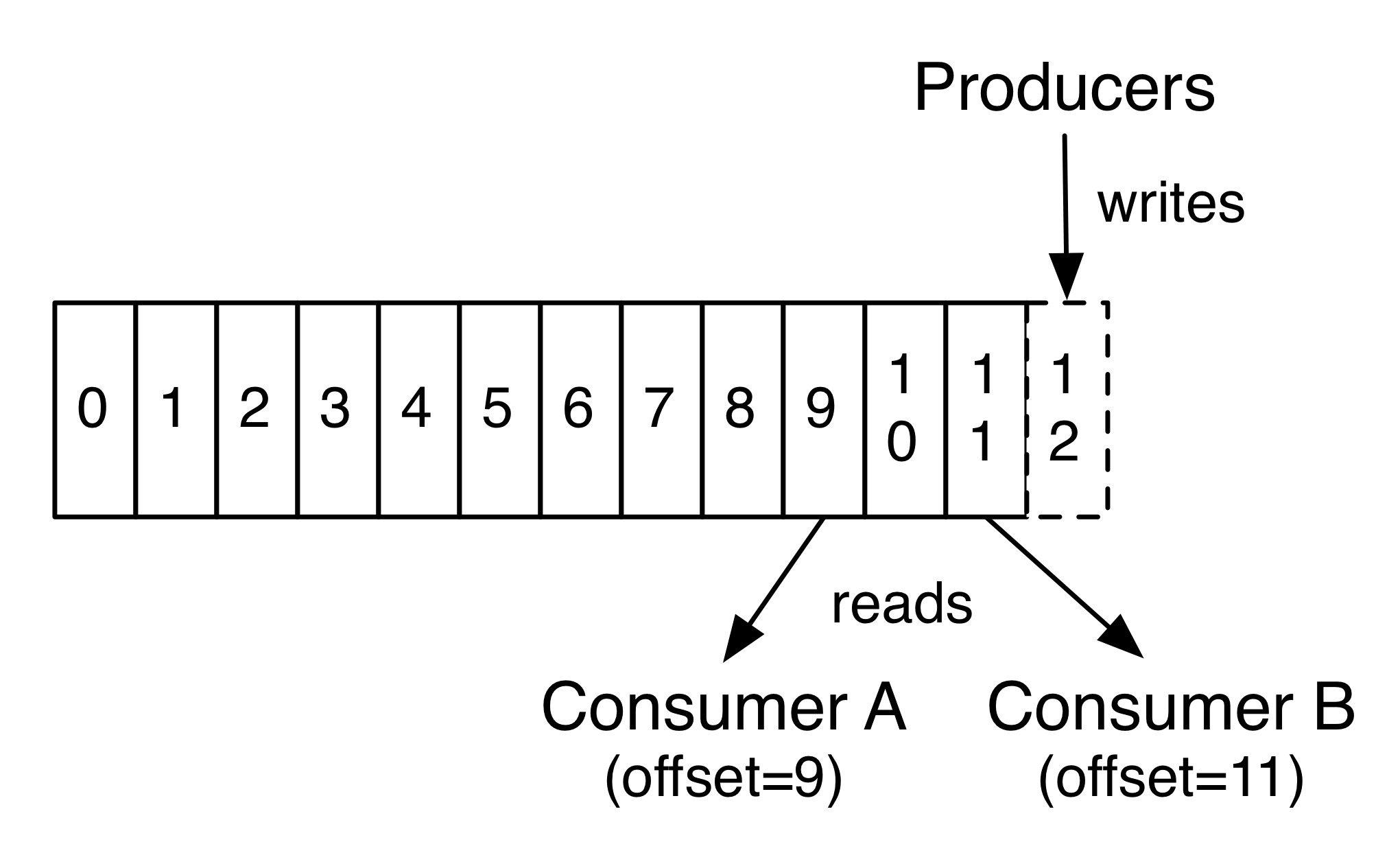
사실, Consumer당 기준으로 유지되는 메타 데이터는 Log에서 해당 Consumer의 Offset 또는 위치입니다.
이 Offset은 Consumer에 의해 제어됩니다.
일반적으로 Consumer는 레코드를 읽을 때 선형적으로 Offset을 진행하지만,
실제로는 위치가 Consumer에 의해 제어되므로 원하는 순서대로 레코드를 소비할 수 있습니다.
예를 들어 Consumer는 과거의 데이터를 다시 처리하는 하기 위해 이전의 Offset을 재설정하거나 가장 최근의 레코드로 건너 뛰고 현재 소비를 시작할 수 있다.
이러한 기능의 결합은 Kafka Consumer가 비용이 매우 저렴하다는 것을 의미합니다.
클러스터 또는 다른 Consumer에게 큰 영향을 미치지 않고 출입할 수 있습니다.
예를 들어, 우리의 Command line Tools처럼 기존 Consumer들로부터 소비되어진 어떤 Topic의 내용을 변경없이 사용할 수 있다.
Log의 Partition은 여러 가지 용도로 사용됩니다. 첫째, Log를 단일 서버에 맞는 크기 이상으로 확장할 수 있습니다.
각 개별 Partition은 호스트하는 서버에 적합해야하지만 Topic에 많은 Partion이 있어 임의의 양의 데이터를 처리할 수 있습니다.
두번째는 병렬 처리 단위로 작동합니다.
Distribution
Log의 Partition은 Kafka 클러스터의 서버를 통하여 배포되며 각 서버는 데이터와 Partition 공유에 대한 요청을 처리한다.
각 Partition은 장애 허용을 위해 구성 가능한 수의 서버에 복제됩니다.
각 Partition에는 "Leader"역할을 하는 서버와 "Follower"역할을 하는 0개 이상의 서버가 있습니다.
Leader는 Follower가 Leader를 수동적으로 복제하는 동안 파타션에 대한 모든 읽기 및 쓰기 요청을 처리합니다.
Leader가 실패하면 Follower 중 하나가 자동으로 새로운 리더가 됩니다.
각 서버는 일부 Partition의 Leader와 다른 서버의 Follower로 작동하므로 로드가 클러스터 내에서 잘 균형을 이룹니다.
Producers
Producer는 선택한 Topic에 데이터를 게시합니다.
Producer는 Topic 내에서 어떤 Partition에 어떤 레코드를 할당할지 선택해야합니다.
이는 Balance Load를 맞추기 위해 round-robin방식으로 수행하거나 일부 의미적 Partition 함수(레코드의 일부 키를 기반으로 함)에 따라 수행할 수 있습니다.
두 번째로 Partitioning을 더 많이 사용합니다.
Consumers
Consumer는 Consumer 그룹이름을 사용하여 레이블을 지정하고 Topic에 게시된 각 레코드는 구독하는 각 Consumer 그룹 내의 하나의 Consumer 인스턴스에 전달됩니다.
Consumer 인스턴스는 별도의 프로세스 또는 별도의 시스템에 있을 수 있습니다.
모든 Consumer 인스턴스가 동일한 Consumer 그룹을 갖는 경우 레코드는 Consumer 인스턴스보다 효과적으로 로드 밸런싱됩니다.
모든 Consumer 인스턴스가 서로 다른 Consumer 그룹을 갖고 있으면 각 레코드가 모든 Consumer 프로세스에 브로드 캐스팅됩니다.
<내용>
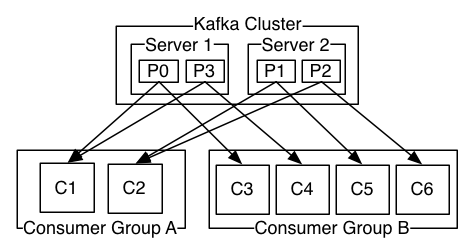
2개의 Consumer 그룹이 있는 4개의 Partiton (P0-P3)을 호스팅하는 2대의 서버 Kafka 클러스터, Consumer 그룹 A에는 두 개의 Consumer 인스턴스가 있고 그룹 B에는 네 개의 인스턴스가 있습니다.
그러나 더 일반적으로, 우리는 Topic이 각각의 "Logical Subscriber"에 대해 하나씩 적은 수의 Consumer 그룹을 가지고 있음을 발견했습니다.
각 그룹의 확장성과 내결함성을 위한 많은 Consumer 인스턴스로 구성됩니다.
Subscriber가 단일 프로세스 대신 Consumer 클러스터인 publish-subscribe 의미론에 불과합니다.
카프카에서 소비가 구현되는 방식은 Log의 Partition을 Consumer 인스턴스로 나누어 각 인스턴스가 어느 시점에서든 Partition의 "Fair Share"를 독점적으로 사용하는 것입니다.
이 그룹 구성원을 유지하는 이 프로세스는 Kafka 프로토콜에 의해 동적으로 처리됩니다.
새 인스턴스가 그룹에 참여하면 그룹의 다른 구성원으로부터 일부 Partition을 인계받습니다.
인스턴스가 종료되면 해당 Partition이 나머지 인스턴스에 배포됩니다.
카프카는 한 Topic의 다른 Partition 사이가 아니라 한 Partition 내의 레코드에 대해서만 전체 주문을 제공합니다.
대부분의 응용 프로그램에서는 Key단위로 데이터를 분할하는 기능과 함께 Partition 단위의 순서만으로 충분합니다.
그러나 레코드에 대한 전체 순서가 필요한 경우 이는 하나의 Partition만 있는 항목으로 달성할 수 있습니다.
단, 이는 Consumer 그룹당 하나의 Consumer 프로세스를 의미합니다.
Messaging 시스템으로서의 Kafka
카프카의 스트림 개념은 기존의 엔터프라이즈 메시징 시스템과 어떻게 비교되는가?
메시징에는 전통적으로 두 가지 모델이 있습니다.
Queuing과 Publish-Subscribe입니다.
대기열에서 Consumer 풀은 서버에서 읽을 수 있으며 각 레코드는 그 중 하나에 저장됩니다.
Publish-Subscribe에서 레코드가 모든 사용자에게 브로드 캐스팅됩니다.
이 두 모델에는 각각 강점과 약점이 있습니다.
대기열 처리 기능을 사용하면 여러 Consumer 인스턴스에서 데이터 처리를 나눌 수 있으므로 처리 규모를 확장할 수 있습니다.
유감스럽게도 대기열은 Multi-Subscriber가 아닙니다.
한 프로세스가 사라진 데이터를 읽으면 대기열이 여러 Subscriber가 아닙니다.
Publish-Subscribe를 사용하면 데이터를 여러 프로세스에 브로드 캐스트 할 수 있지만 모든 메시지가 모든 Subscriber에게 전달되기 때문에 확장 처리 방법이 없습니다.
카프카의 Consumer 그룹 개념은이 두 개념을 일반화합니다.
대기열에서와 마찬가지로 Consumer 그룹은 프로세스 모음 (Consumer 그룹의 구성원)을 통해 처리를 나눌 수 있습니다.
Publish-Subscribe와 마찬가지로 Kafka를 사용하면 여러 Consumer 그룹에 메시지를 브로드 캐스트 할 수 있습니다.
카프카의 모델의 장점은 모든 Topic이 이러한 속성을 모두 갖추고 있다는 것입니다.
즉, 처리 규모를 조정할 수 있고 Multi-Subscriber이기도합니다. 하나 또는 둘 다를 선택할 필요가 없습니다.
Kafka는 전통적인 메시징 시스템보다 더 강력한 주문 보증을 제공합니다.
전통적인 대기열은 서버에서 순서대로 레코드를 보유하고, 여러 Consumer가 대기열에서 소모하는 경우 서버는 저장된 순서대로 레코드를 전달합니다.
그러나 서버가 레코드를 순서대로 전달하더라도 레코드는 비동기적으로 Consumer에게 전달되므로 서로 다른 Consumer에게 순서가 잘못될 수 있습니다.
이것은 실제로 병렬 소비가 발생하면 레코드의 순서가 손실된다는 것을 의미합니다.
메시징 시스템은 대기열에서 하나의 프로세스만 사용할 수 있는 "Exclusive Consumer"라는 개념을 사용하여 이 문제를 해결하기도하지만 처리 과정에서 병렬 처리가 없다는 것을 의미합니다.
Topic내에서 병렬 처리 개념(Partition)을 가짐으로써 카프카는 Consumer 프로세스 풀에 대해 주문 보증과 로드 밸런싱을 모두 제공할 수 있습니다.
이는 Topic의 Partition을 Consumer 그룹의 Consumer에게 할당하여 각 Partition이 그룹의 정확히 한 Consumer에 의해 소비되도록하여 수행됩니다.
이렇게함으로써 우리는 Consumer가 해당 Partition의 유일한 Subscriber임을 확인하고 순서대로 데이터를 소비합니다.
Partition이 많으므로 많은 Consumer 인스턴스에서로드의 균형을 유지합니다.
그러나 Consumer 그룹에는 Partition보다 더 많은 Consumer 인스턴스가 있을 수 없습니다.


 <내용>
<내용>
 <내용>
<내용>
 <내용>
<내용>
 <내용>
<내용>
 <내용>
<내용>