

Flume Testing
24 Jan 2019 | IoT포스팅
Apache Flume
Implementation Component of Flume Component
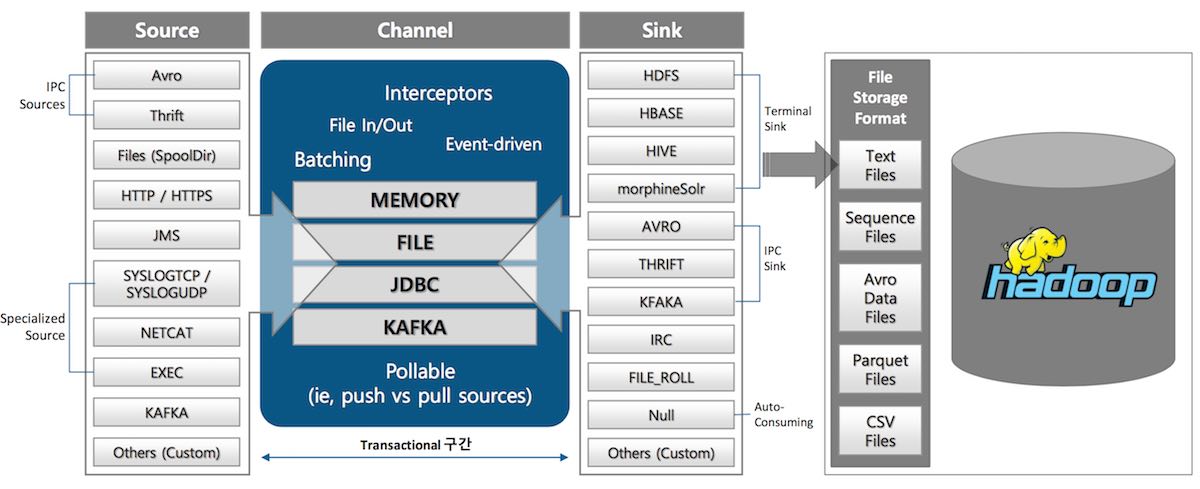
| Apache Flume | 벌목장 Flume |
|---|---|
| Apache Flume이란 | 전통적인 벌목장의 플룸이란 |
| 여러 서버에 | 여러 벌목장에 |
| 설치되는 소프트웨어로 | 설치되는 통나무 운반용 수로(플룸)로 |
| 수집한 로그를 | 벌목한 통나무(로그)를 |
| 원격지의 Data Lake로 | 산 아래 강으로 |
| 전송하는 비동기 채널입니다. | 운반하는 수로입니다. |
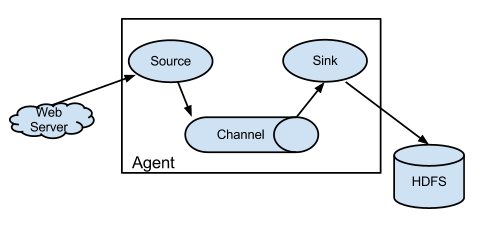
Flume Converging Flow
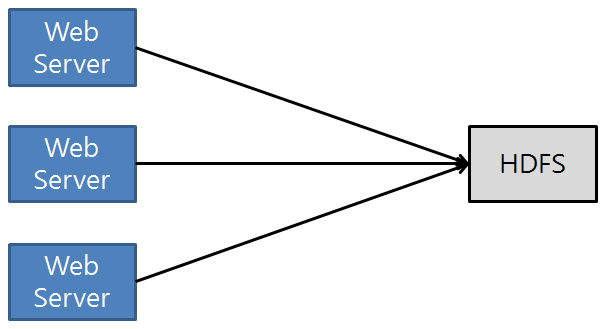
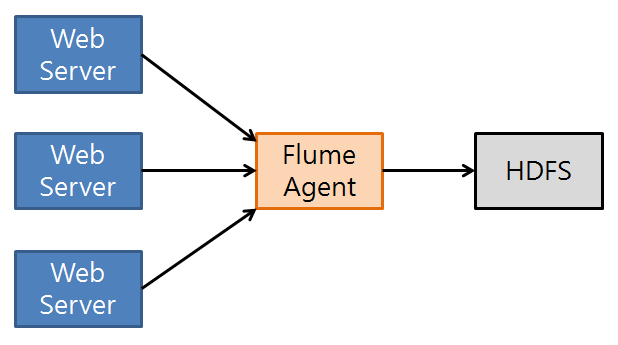
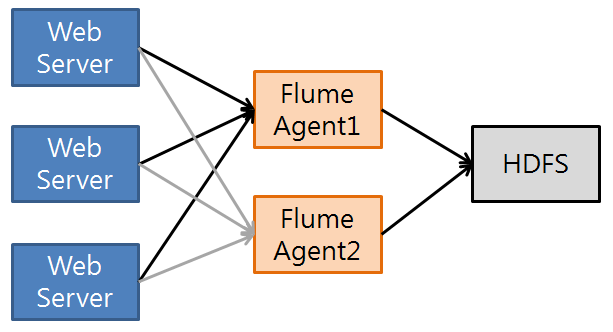
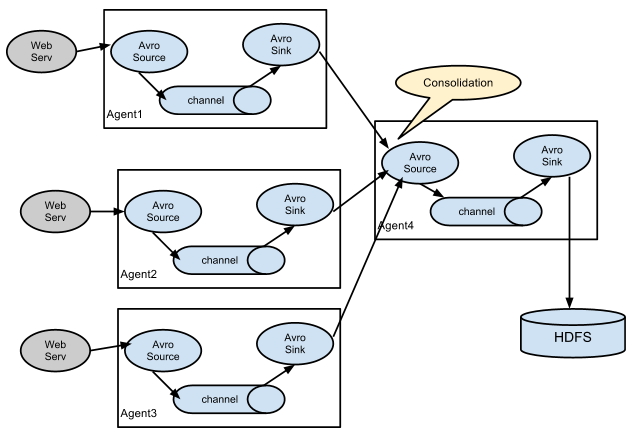 <대량 로그를 처리를 위한 일반적인 구조>
<대량 로그를 처리를 위한 일반적인 구조>
Flume 설치
Flume 설치 파일은 다음 URL에서 다운로드 할 수 있습니다. 2019.01 현재 최신버전은 1.9.0입니다. 설치 파일은 gz파일 형태로 배포됩니다. https://flume.apache.org/download.html 설치는 압축을 푸는 것으로 완료됩니다.
$ wget http://apache.mirror.cdnetworks.com/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
$ sudo cp apache-flume-1.9.0-bin.tar.gz /usr/local/lib/apache-flume-1.9.0-bin.tar.gz
$ sudo tar -xvf apache-flume-1.9.0-bin.tar.gz
$ sudo mv apache-flume-1.9.0-bin/ flume/
$ sudo add-apt-repository ppa:openjdk-r/ppa
$ sudo apt update
$ sudo apt install openjdk-8-jre openjdk-8-jdk
$ sudo update-alternatives --config java
$ sudo update-alternatives --config javac
$ sudo update-alternatives --get-selections | grep openjdk
$ export FLUME_HOME="/usr/local/lib/flume"
$ export FLUME_CONF_DIR="$FLUME_HOME/conf"
$ export FLUME_CLASSPATH="$FLUME_CONF_DIR"
$ export PATH="$FLUME_HOME/bin:$PATH"
$ export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
Flume 기본 설정과 실행 방법
Flume으로 서버로그를 Hadoop에 수집하는 예제를 소개합니다. Flume은 에이전트 노드와 컬렉트 노드에 설치되었음을 가정합니다.
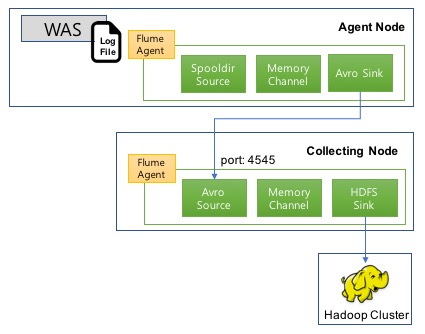
Agent 노드 Flume 설정 및 실행
로그를 수집하는 에이전트 노드에 다음과 같은 Flume 설정을 추가합니다. 파일명은 flume.conf입니다. 다음 예제는 /data/waslogs에 추가되는 로그 파일을 컬렉트 노드에 전송하는 설정입니다. 전송 포맷은 avro입니다. 이 설정 파일은 /usr/local/lib/flume/conf에 하는 것으로 가정합니다.
sudo vim AgentFlume.conf
agentDataSource.sources = logsrc
agentDataSource.channels = logChannel
agentDataSource.sinks = avroSink
# Source : Log
agentDataSource.sources.logsrc.type = spooldir
agentDataSource.sources.logsrc.channels = logChannel
agentDataSource.sources.logsrc.spoolDir = /data/waslogs
# Sink : Avro
agentDataSource.sinks.avroSink.type = avro
agentDataSource.sinks.avroSink.channel = logChannel
agentDataSource.sinks.avroSink.hostname = 142.3.3.1
agentDataSource.sinks.avroSink.port = 4545
# Channel : Memory Channel
agentDataSource.channels.logChannel.type = memory
agentDataSource.channels.logChannel.capacity = 100
################################################
cd /usr/local/lib/flume
./bin/flume-ng agent --conf /usr/local/flume/conf --conf-file ./conf/AgentFlume.conf --name agent01
Collecting 노드 Flume 설정 및 실행
다음은 컬렉트 노드의 flume 설정입니다. avro 포멧으로 유입되는 로그를 수집항 hadoop에 저장하는 구성입니다. 파일명은 flume.conf입니다. 이 설정 파일은 /usr/local/lib/flume/conf에 하는 것으로 가정합니다.
sudo vim CollectingFlume.conf
agentDataCollector.sources = targetSource
agentDataCollector.channels = targetChannel
agentDataCollector.sinks = targetSink
# Source : Avro
agentDataCollector.sources.targetSource.type = avro
agentDataCollector.sources.targetSource.channels = targetChannel
agentDataCollector.sources.targetSource.bind = 142.3.3.1
agentDataCollector.sources.targetSource.port = 4545
# Sink : HDFS
agentDataCollector.sinks.targetSink.type = hdfs
agentDataCollector.sinks.targetSink.channel = memoryChannel
agentDataCollector.sinks.targetSink.hdfs.path = hdfs://142.3.3.5:9000/data/stats/%Y-%m-%d/%H
agentDataCollector.sinks.targetSink.hdfs.fileType = DataStream
agentDataCollector.sinks.targetSink.writeFormat = Text
agentDataCollector.sinks.targetSink.hdfs.filePrefix = access_log
agentDataCollector.sinks.targetSink.hdfs.fileSuffix = .log
agentDataCollector.sinks.targetSink.hdfs.threadsPoolSize = 10
agentDataCollector.sinks.targetSink.hdfs.rollInterval = 30
agentDataCollector.sinks.targetSink.hdfs.round = false
local_agent.sinks.localHdfsSink.hdfs.roundValue = 5
local_agent.sinks.localHdfsSink.hdfs.roundUnit = minute
# Channel : Memory
agentDataCollector.channels.targetChannel.type = memory
agentDataCollector.channels.targetChannel.capacity = 100
################################################
cd /usr/local/lib/flume
./bin/flume-ng agent --conf /usr/local/flume/conf --conf-file ./conf/CollectingFlume.conf --name agent02
Flume의 유연한 구성 그리고 Kafka
Flume은 다양한 Source와 Sink 타입을 제공합니다. 이런 구현체를 이용하여 다양한 형태의 Data Flow를 디자인할 수 있습니다. 아래의 그림은 일반적인 Flume 데이터 흐름 모델입니다.
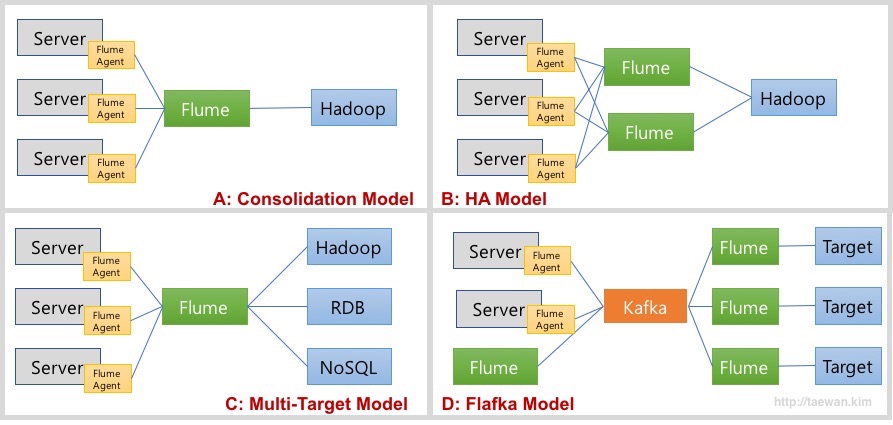
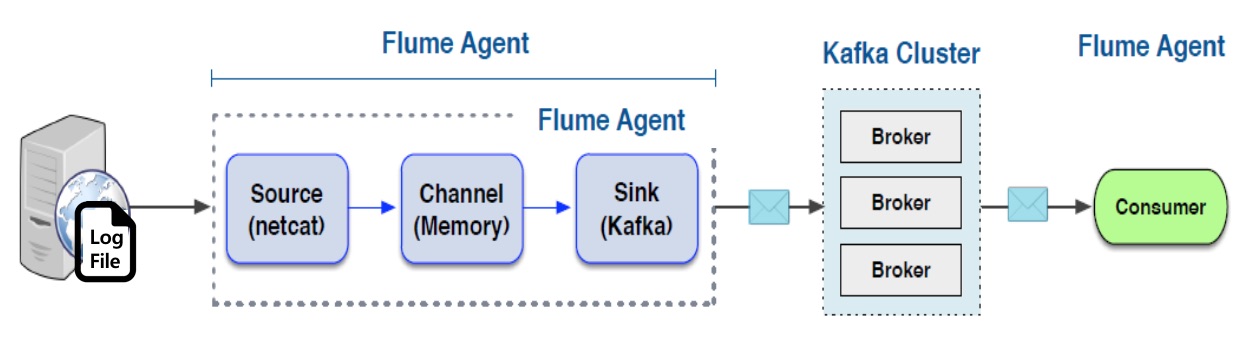
A 모델: Consolidation Model 여러 서버로부터 로그를 통합하여 수집하고 저장하는 모델 각 서버에 Flume Agent가 설치되어 로그를 통합 Flume에 저장 통합 Flume은 지정된 목적지에 저장 B 모델: HA 모델 A 모델에서 통합 Flume 장애의 SPOF(단일 장애 포인트)에 대한 보완 고가용성을 위해서 통합 Flume을 이중화 C 모델: Multi-Target Model A 모델의 목적지를 복수로 지정 D 모델: Flafka Model Flume이 Kafka의 Producer와 Consumer 역할 수행 통합 Flume을 Kafka로 대체하여 고가용성 및 확장성, 유연성을 확보 Flume을 이용하여 Kafka 개발 요소 제거Flume의 가장 큰 취약점은 데이터의 안정성입니다. Flume은 Channel로 메모리와 파일 그리고 JDBC를 제공합니다. 메모리 타입은 처리 성능은 좋지만, Flume 장애 발생 시 데이터가 유실의 문제가 있습니다. 반면 파일 타입을 사용하면 데이터 안정성은 향상되지만, 성능이 크게 떨어집니다. 그리고 고가용성 모드로 관리하기 어렵다는 것입니다. 이러한 문제는 Flume과 Kafka를 결합함으로써 해결할 수 있습니다. 최근에 로그/이벤트 수집 환경을 구성 시 Flume만으로 구성하는 경우는 거의 없습니다. 아래의 그림와 같이 Flafka Model을 사용합니다.
Flume 모니터링
Flume을 모니터링하는 방법은 기본적으로 3가지가 있습니다.Ganglia JMX JSON ReportingFlume은 JSON 리포팅 기능을 제공합니다. flume 실행 시 -Dflume.monitoring.type=http 옵션을 추가하여 웹 기반 모니터링이 가능합니다. 리포팅 기본 포트는 41414이며 변경 가능합니다. http://<모니터링 대상 Flum IP>:41414/metrics 호출하면 아래와 같은 정보가 출력됩니다.
{
"SINK.avroSink":{
"BatchCompleteCount":"133",
"ConnectionFailedCount":"0",
"EventDrainAttemptCount":"13300",
"ConnectionCreatedCount":"1",
"Type":"SINK",
"BatchEmptyCount":"0",
"ConnectionClosedCount":"0",
"EventDrainSuccessCount":"13300",
"StopTime":"0",
"StartTime":"1398215901251",
"BatchUnderflowCount":"0"
},
"SOURCE.otvSource":{
"OpenConnectionCount":"0",
"Type":"SOURCE",
"AppendBatchAcceptedCount":"133",
"AppendBatchReceivedCount":"133",
"EventAcceptedCount":"13300",
"AppendReceivedCount":"0",
"StopTime":"0",
"StartTime":"1398215901332",
"EventReceivedCount":"13300",
"AppendAcceptedCount":"0"
},
"CHANNEL.otvChannel":{
"EventPutSuccessCount":"13300",
"ChannelFillPercentage":"0.0",
"Type":"CHANNEL",
"EventPutAttemptCount":"13300",
"ChannelSize":"0",
"StopTime":"0",
"StartTime":"1398215901247",
"EventTakeSuccessCount":"13300",
"ChannelCapacity":"100",
"EventTakeAttemptCount":"13301"
}
}
가져온곳: http://www.nextree.co.kr/p2704/ http://taewan.kim/post/flume_images/