

Web Architecture Basic
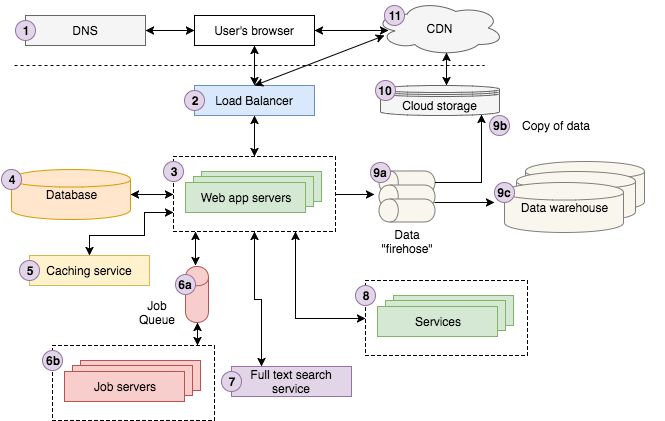
03 Jan 2019 | Daily사용자는 구글에 “Strong Beautiful Fog And Sunbeams In The Forest”를 검색한다. 첫 번째 결과는 우리 선도하는 stock and vector site인 스토리블록에서 나올 것이다. 사용자가 결과를 클릭하면 브라우저는 자세한 이미지를 보여주는 페이지로 재전송한다. 뒤에서는 사용자의 브라우저가 요청을 DNS 서버로 보내 스토리블록에 어떻게 접속할 지 조사하고, 요청을 보낸다. 요청은 우리 로드 밸런서를 hit해, 요청을 처리하는 시점에 운영하고 있는 10개 남짓되는 서버중 하나를 무작위로 선택한다. 웹 서버는 캐싱 서비스에서 이미지에 대한 정보를 조사하고 데이터베이스에서 나머지 데이터를 가져온다. 이미지에 대한 color profile을 아직 계산하지 않았음을 인지했으므로, “color profile” 잡을 잡 큐에 보내, 잡 서버가 비동기로 처리해서 결과를 가지고 적절하게 데이터베이스를 갱신하도록 한다. 다음으로, 사진의 제목을 입력으로 사용해 풀 텍스트 검색 서비스에 요청을 보내 유사한 사진을 찾는 시도를 한다. 사용자가 스토리블록 회원으로 로그인을 했으면 계정 정보를 계정 서비스에서 찾는다. 마지막으로, 클라우드 저장 시스템에서 페이지 뷰 이벤트가 저장되도록 데이터 파이어호스로 보내고 최종적으로 데이터 웨어하우스에 로드되도록 하는데, 이 작업은 분석가들이 비즈니스에 대한 답을 찾는데 도움을 준다. 서버는 이제 뷰를 HTML로 렌더링하고 사용자 브라우저에 다시 보내는데, 우선 로드 밸런서를 거치도록 한다. 페이지는 우리의 클라우드 저장 시스템에 로드한 자바스크립트와 CSS 자원을 포함하고, 이들은 CDN에 연결되어, 사용자 브라우저는 CDN을 통해 이런 컨텐츠를 받는다. 최종적으로, 브라우저는 사용자가 볼 수 있게 페이지를 렌더링한다.
 <내용>
<내용>
1. DNS
DNS는 “도메인 네임 서버"를 의미하는, 월드 와이드 웹이 가능하게 하는 기간 기술이다. 기초를 넘지 않는 수준에서 DNS는 도메인 이름(예를 들어 google.com)에 대한 IP 주소(예를 들어 85.129.83.120) 키/값 조사를 제공하는데, 이 작업은 컴퓨터가 요청을 적절한 서버로 보낼 때 필요하다. 전화번호부로 유추해보면, 도메인 이름과 IP 주소간의 차이는 “존 도에게 전화해"와 “201–867–5309로 전화해"의 차이와 같다. 옛날에 존의 전화번호를 찾기 위해 전화번호부가 필요했듯이, 도메인에 대해서는 IP 주소를 찾기 위해 DNS를 조사하는게 필요하다. 그러므로, DNS는 인터넷을 위한 전화번호부로 간주할 수 있다.2. Load Balancer
로드 밸런싱의 자세한 사항을 알아보기 전에, 수평 vs. 수직 확장에 대해 논의하기 위해 한발짝 물러설 필요가 있다. 그것들이 무엇이고 무슨 차이가 있는가? 아주 간단하게, 이 스택오버플로우 포스트로 들어가보면, 수평 확장은 자원 풀에 더 많은 기계를 더해 스케일을 늘리는 걸 의미하는 반면 “수직" 확장은 더 많은 처리 능력(예를 들어 CPU, 램)을 이미 존재하는 기계에 더해 스케일을 늘리는 일이다. 웹 개발에서, 당신은 (거의) 항상 수평 확장을 원할텐데, 왜냐하면 간단히 말해, 자원들이 망가지기 때문이다. 서버는 무작위로 멈춘다. 네트워크는 속도가 느려진다. 전체 데이터 센터는 종종 접속이 끊어진다. 하나 이상의 서버를 갖는다는 건 항상 정전에 대비해 어플리케이션이 끊임없이 동작하게 할 계획을 가능하게 한다. 다른 말로, 당신의 앱은 “내고장성”을 갖는다. 두 번째로, 수평 확장은 서로 다른 어플리케이션 백엔드(웹 서버, 데이터베이스, 어떤 서비스 등)들이 서로 다른 서버에서 동작해, 최소한 짝을 지어 운영하게 한다. 마지막으로, 수직 확장이 더 이상 불가능할 때 확장을 할 수 있게 한다. 세상에 당신의 모든 앱의 계산을 가능하게 할 만큼 강력한 컴퓨터는 없다. 훨씬 더 작은 규모의 회사에 적용하기는 하지만, 전형적인 예로 구글 검색 플랫폼을 생각해보자. 스토리블록은 예를 들어 어떤 시점에 150에서 400개의 AWS EC2 인스턴스로 동작한다. 전체 처리 능력을 수직 확장으로 제공하는 건 매우 도전적인 일이다. 이제, 로드 밸런서로 돌아가자. 로드 밸런서는 수평 확장이 가능하게 하는 마법의 소스이다. 로드 밸런서는 들어오는 요청을 전형적인 각각의 복제/미러 이미지인 많은 어플리케이션 서버 중 하나로 전달하고 앱 서버의 응답을 다시 클라이언트에게 보낸다. 그들 중 하나는 요청을 같은 방식으로 처리해, 요청을 전체 서버 집합에 분산하고 어떤 서버도 과부하가 걸리지 않게 한다. 이게 다이다. 개념적으로 로드 밸런서는 꽤 직관적이다. 이면에서는 확실히 복잡하지만, 101 버전에서는 더 이상 깊이 들어갈 필요는 없다.3. Web Application Servers
고 수준 웹 어플리케이션 서버는 비교적 서술하기 간단하다. 웹 어플리케이션 서버들은 사용자 요청을 다루는 핵심 비즈니스 로직을 실행하고 HTML을 사용자 브라우저로 다시 보낸다. 작업을 하기 위해, 대개 데이터베이스, 캐싱 계층, 잡 큐, 검색 서비스, 다른 마이크로서비스, 데이터/로깅 큐 등 다양한 종류의 백엔드 인프라스트럭쳐와 통신을 한다. 위에서 언급했듯이, 사용자 요청을 처리하기 위해 적어도 두 개나 더 많은 서버들을 로드 밸런서에 결합한다. 앱 서버 구현은 특정 언어(Node.js, 루비, PHP, 스칼라, 자바, C# .NET 등)와 해당 언어의 웹 MVC 프레임워크(Node.js의 Express, 루비 온 레일스, 플레이 포 스칼라, PHP의 라라벨 등)를 선택할 필요가 있다. 하지만, 이런 언어와 프레임워크에 대해 자세히 알아보는 건 이 문서의 범위를 벗어난다.4. Database Servers
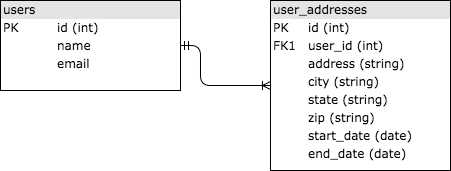
모든 현대적인 웹 어플리케이션은 하나 이상의 데이터베이스를 정보를 저장하기 위해 이용한다. 데이터베이스는 자료 구조를 정의하고, 새 데이터를 입력하고, 존재하는 데이터를 찾고, 갱신하거나 삭제하고 데이터 전반에 걸친 동작을 수행하는 등의 방법을 제공한다. 대부분 웹 앱 서버는 잡 서버가 그렇듯 하나의 데이터베이스와 직접 이야기한다. 추가로, 각 백엔드 서비스는 나머지 어플리케이션과 분리된 자체 데이터베이스를 가질 수 있다. 각 아키텍쳐 컴포넌트에 대해 특정 기술을 자세히 보는 걸 피하는 반면, 데이터베이스의 다음 레벨: SQL과 NoSQL의 세부 사항을 언급하지 않는 실수를 할 수 있다. SQL은 “구조화된 쿼리 언어"를 의미하고, 폭넓게 접근 가능한 관계형 데이터 집합에 쿼리를 보내는 표준 방법을 제공하기 위해 1970년대에 만들어졌다. SQL 데이터베이스는 데이터를 테이블에 저장하는데, 테이블들은 공통 ID, 보통 정수형값으로 서로 연결된다. 사용자의 주소 정보를 저장하는 간단한 예를 살펴보자. 아마 users와 user_addresses, 사용자 id로 연결된 두 개의 테이블을 가지고 있을 것이다. 단순한 버전을 위해 아래 그림을 보자. 테이블은 연결되었는데, user_addresses의 user_id 열이 users 테이블의 id 열에 “외래 키"가 된다.
 <내용>
<내용>
5. Caching Service
캐싱 서비스는 단순하게 키/값 데이터 저장을 제공해 정보를 저장하고 찾는 작업을 거의 O(1)에 가능하게 한다. 어플리케이션은 대개 캐싱 서비스를 이용해 비싼 작업의 결과를 저장해서 다음에 다시 필요할 때 재작업을 하는 대신 캐시에서 결과를 가져올 수 있게 한다. 어플리케이션은 데이터베이스 쿼리, 외부 서비스에 대한 요청, 주어진 URL에 대한 HTML등 여러가지에서 만든 결과를 캐시할 수 있다. 실세계 어플리케이션에서 가져온 몇 가지 예는 다음과 같다: 1. 구글은 매번 재작업을 하는 대신 “개"나 “테일러 스위프트"같은 흔한 검색 쿼리 결과를 캐시한다. 2. 페이스북은 로그인할 때 포스트 데이터, 친구 등 데이터 대부분을 캐시한다. 페이스북의 캐싱 기술에 대한 자세한 내용은 여기를 읽어보자. 3. 스토리블록은 서버측 리액트 렌더링, 검색 결과, 입력에 선행하는 결과 등으로부터 만들어지는 HTML 출력을 캐시한다. 두 가지 널리 사용하는 캐싱 서버 기술은 레디스와 멤캐시이다. 다른 포스트에서 더 자세한 내용을 다룰 예정이다.6. Job Queue & Servers
대부분의 웹 어플리케이션은 사용자 요청에 직접 연관된 응답을 하는게 아니라면 뒤에서 비동기로 동작하는 작업이 필요하다. 예를 들어 구글은 검색 결과를 돌려주기 위해 전체 인터넷을 크롤하고 색인을 할 필요가 있다. 이 작업은 검색할 때마다 매번 하지 않는다. 대신, 웹을 비동기적으로 크롤하고, 그에 따라 검색 색인을 갱신한다. 비동기 작업을 가능하게 하는 서로 다른 아키텍쳐가 있지만, 대부분 어디에나 존재하는 건 “잡 큐" 아키텍쳐라고 부르는 것이다. 두 개의 컴포넌트, 동작할 “잡" 큐와 큐의 잡을 동작시킬 하나 이상의 잡 서버(보통 “워커"라고 부른다)로 구성한다. 잡 큐는 비동기로 동작할 필요가 있는 잡 리스트를 저장한다. 가장 단순한 건 선입선출(FIFO) 큐이지만 대부분의 어플리케이션은 어떤 종류의 우선순위 큐잉 시스템이 필요하게 된다. 어떤 종류의 규칙적인 스케쥴이나 사용자 동작의 결과로나, 앱이 잡이 동작할 필요가 있을 때마다, 적절한 잡을 큐에 더하는 일만 한다. 예를 들어 스토리블록은, 잡 큐를 이용해 우리 판매 시장을 지원할 필요가 있는 여러가지 후방 작업을 강화한다. 비디오나 사진을 인코딩하고, CSV에서 메타데이터 태깅을 진행하고, 사용자 통계를 집계하고, 패스워드 설정 이메일을 보내는 등의 일을 위해 잡을 동작시킨다. 단순한 FIFO 큐로 시작했지만 우선 순위 큐로 개선해 패스워드 설정 이메일같이 빠른 시간안에 완료해야 하는 시간에 민감한 작업을 확실히 하는데 사용한다. 잡 서버는 잡을 진행한다. 잡 서버는 잡 큐를 조사해 할 일이 있는지 결정하고 있다면 큐에서 잡을 가져와 실행한다. 선택할 수 있는 언어와 프레임워크는 웹 서버만큼이나 다양하기 때문에 여기서는 세부사항은 보지 않는다.7. Full-text Search Service
대부분은 아니지만 많은 웹 앱이 제공하는 어떤 종류의 검색 특성은 사용자가 텍스트 입력(보통 “쿼리"라고 부르는)을 제공하고 앱은 가장 “관련있는" 결과를 돌려주는 것이다. 이 기술은 전형적으로 “풀 텍스트 검색”으로 부르는 기능을 제공하는데, 인버티드 인덱스를 이용해 쿼리 키워드를 포함하는 문서를 빠르게 검색하도록 한다.
 <내용>
<내용>
8. Services
앱이 특정 스케일에 다다르면, 별도 어플리케이션으로 운영하게 분리하는 특정 “서비스"가 될 수 있다. 외부에 노출하지는 않지만 앱은 다른 서비스들과 데이터를 주고받는다. 스토리블록은 예를 들어 여러가지 운영 및 계획된 서비스들이 있다: 1. 계정 서비스는 우리 사이트 전체를 아우르는 사용자 데이터를 저장해, 사이트를 넘나드는 판매 기회를 쉽게 제공하고 좀 더 통합된 사용자 경험을 만든다. 2. 컨텐트 서비스는 모든 비디오, 오디오, 이미지 컨텐트에 대한 메타 데이터를 저장한다. 또 컨텐트를 다운로드하고 다운로드 내역을 볼 수 있는 인터페이스를 제공한다. 3. 지불 서비스는 사용자 신용 카드 지불을 위한 인터페이스를 제공한다. 4. HTML → PDF 서비스 p는 HTML을 받아 대응하는 PDF 문서를 돌려주는 간단한 인터페이스를 제공한다.9. Data
오늘날, 기업은 데이터를 어떻게 잘 이용하느냐에 따라 살고 죽는다. 요즘의 거의 모든 앱은, 특정 스케일에 도달하면, 데이터 파이프라인을 이용해 데이터를 수집하고 저장하고 분석한다. 전형적인 파이프라인은 3가지 주요 단계를 갖는다: 앱은 데이터를 보내고, 대개 사용자와의 교류에 대한 이벤트인 데이터를 데이터를 가져와 처리하는 스트리밍 인터페이스를 제공하는 데이터 “firehose”에 보낸다. 대개 원 데이터는 변환하고, 보강해서 다른 firehose에 보낸다. AWS 키네시스와 카프카가 이런 목적을 위해 사용하는 가장 흔한 두 가지 기술이다. 원 데이터뿐만 아니라 전환/보강한 최종 데이터도 클라우드 스토리지에 저장한다. AWS 키네시스는 원 데이터를 클라우드 저장장치(S3)에 저장하는 작업을 매우 쉽게 설정하는 “firehose”라 부르는 설정을 제공한다. 전환/보강된 데이터는 보통 분석을 위해 데이터 웨어하우스에 로드한다. 우리는 스타트업 세계에서 많은 부분을 차지하고 성장중인 AWS 레드시프트를 사용하는데, 더 큰 회사들은 보통 오라클이나 다른 웨어하우스 기술을 사용한다. 데이터 집합이 충분히 크다면, 분석을 위해 하둡과 유사한 NoSQL 맵리듀스 기술이 필요할 수도 있다. 아키텍쳐 다이어그램에 그리지 않은 다른 단계는 앱과 서비스의 운영 데이터베이스에서 데이터를 데이터 웨어하우스로 로드하는 작업이다. 예를 들어 스토리블록은 비디오블록, 오디오블록, 스토리블록, 계정 서비스, 공헌자 포털 데이터베이스를 매일 밤 레드시프트에 로드한다. 이렇게 분석가들에게 전체적인 데이터셋을 제공해 핵심 비즈니스 데이터와 사용자 교류 이벤트 데이터를 같이 배치한다.10. Cloud Storage
AWS에 따르면, “클라우드 저장장치는 인터넷에서 데이터를 저장하고 접근하고 공유하기 위해 간단하고 확장 가능한 방법이다". 데이터를 저장하고 접근하는데 HTTP를 통해 RESTful API를 사용 가능하다는 점을 제외하면 로컬 파일 시스템을 이용하는 것과 다르지 않다. 아마존 S3는 현존하는 가장 인기있는 클라우드 저장장치이고, 스토리블록에서도 비디오, 사진, 음성, CSS, 자바스크립트, 사용자 이벤트 데이터 등을 저장하는데 광범위하게 사용하고 있다.11. CDN
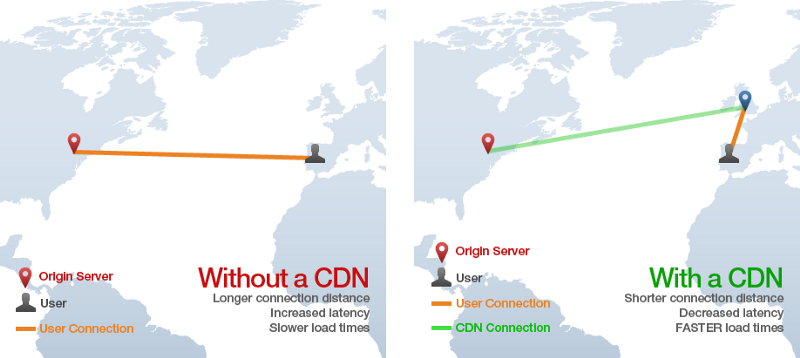
CDN은 “컨텐트 전달 네트워크"를 의미하고, 하나의 원래 서버에서 정적 HTML, CSS, 자바스크립트, 이미지등을 제공하는 것 보다 훨씬 빠른 속도 제공하는 기술이다. 컨텐트를 많은 “edge” 서버에 분산해 사용자가 원래의 서버가 아니라 “edge” 서버에서 자원들을 다운로드 받게 함으로 동작한다. 예를 들어 아래 그림은, 스페인에 있는 사용자가 NYC에 있는 원래의 서버에 요청을 보냈지만, 해당 페이지의 정적 자원은 대서양을 건너는 느린 HTTP 요청을 막기 위해 영국에 있는 “edge” CDN에서 로드되는 걸 보여준다.
 <내용>
<내용>
가져온곳: https://mingrammer.com/translation-10-common-software-architectural-patterns-in-a-nutshell/